XPathをブラウザで取得する
XPath取得ツールでは、ブラウザで取得したXPathの解析や、自分で編集したXPathのチェックができます。
ブラウザで取得する必要があるケース
「Yahoo!路線情報」の【出発欄】のXPathを、XPath取得ツールで取得します。
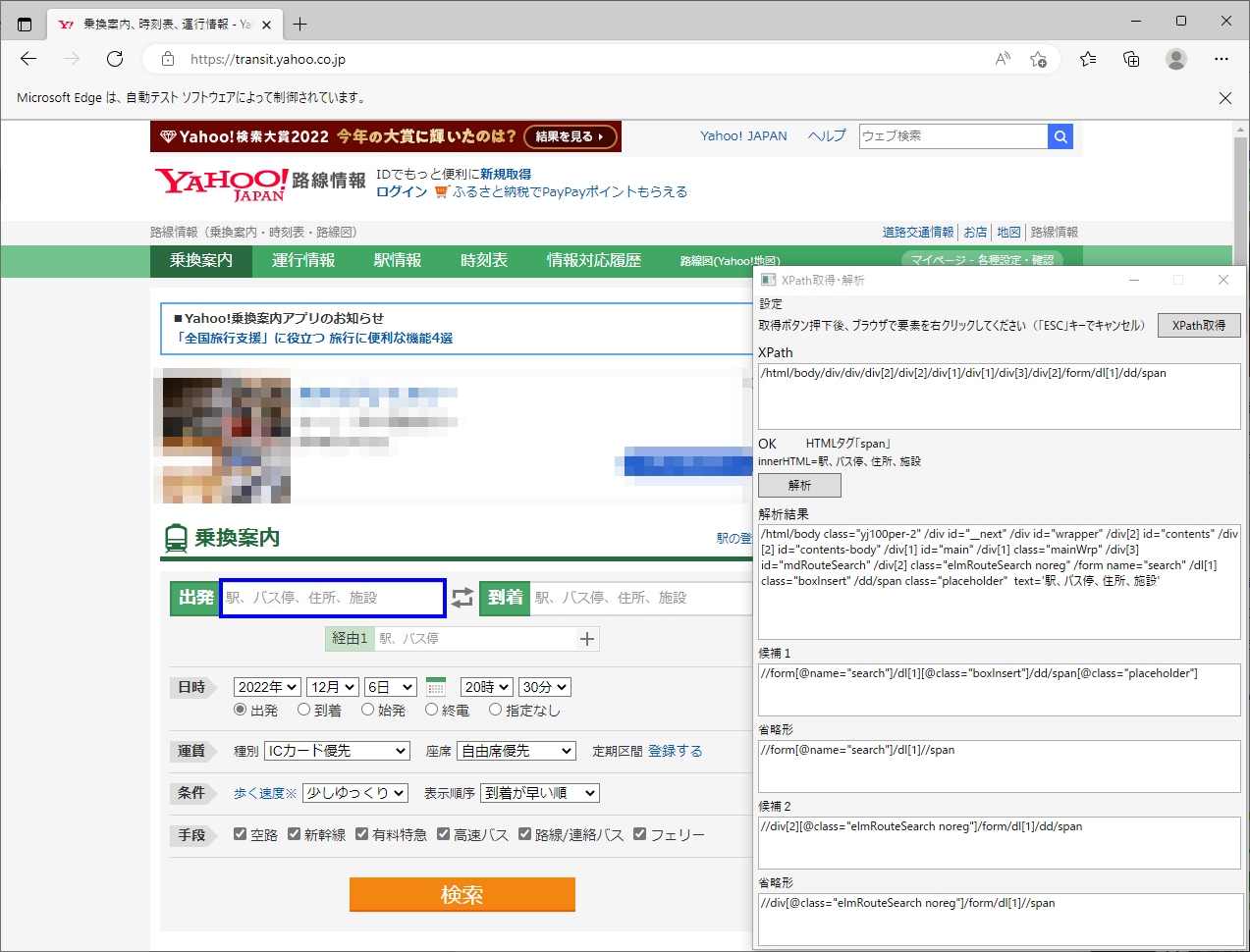
| フルXPath | /html/body/div/div/div[2]/div[2]/div[1]/div[1]/div[3]/div[2]/form/dl[1]/dd/span |
| 解析後 | //form[@name="search"]/dl[1]//span |
操作の実施
得られたXPathで文字入力の操作を試みます。
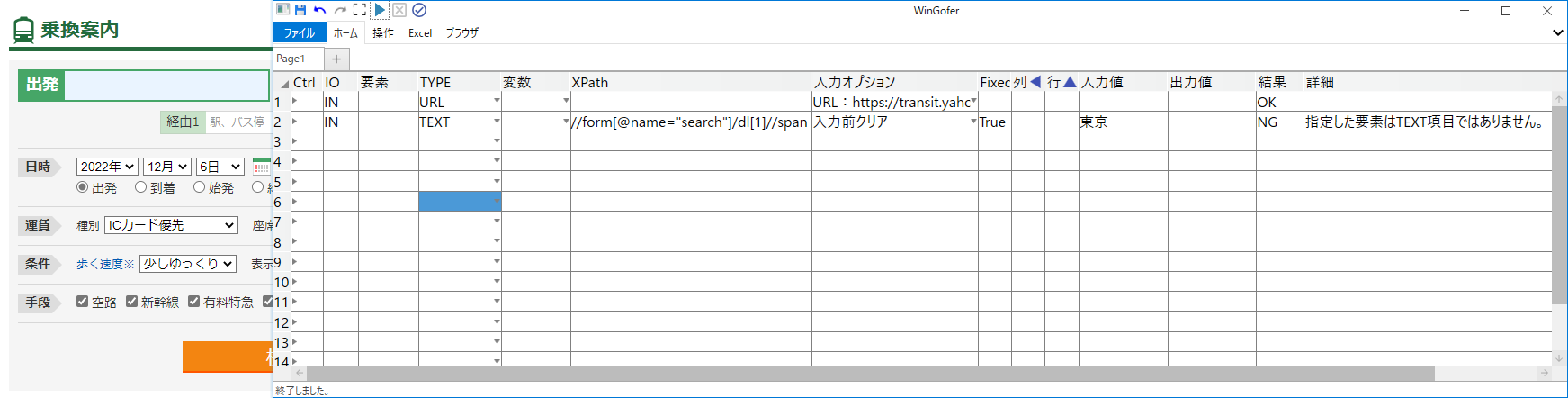
【出発欄】の文字入力に失敗しました。
| 結果 | 詳細 |
|---|---|
| NG | 指定した要素はTEXT項目ではありません。 |
エラーの原因
要素のXPathは、//form[@name="search"]/dl[1]//spanでした。
<span>タグは、HTMLのテキスト要素<input type="text">でないため、文字の入力ができません。
したがって、正しくは<input>タグのXPathを取得する必要があります。
ブラウザでXPathを取得する
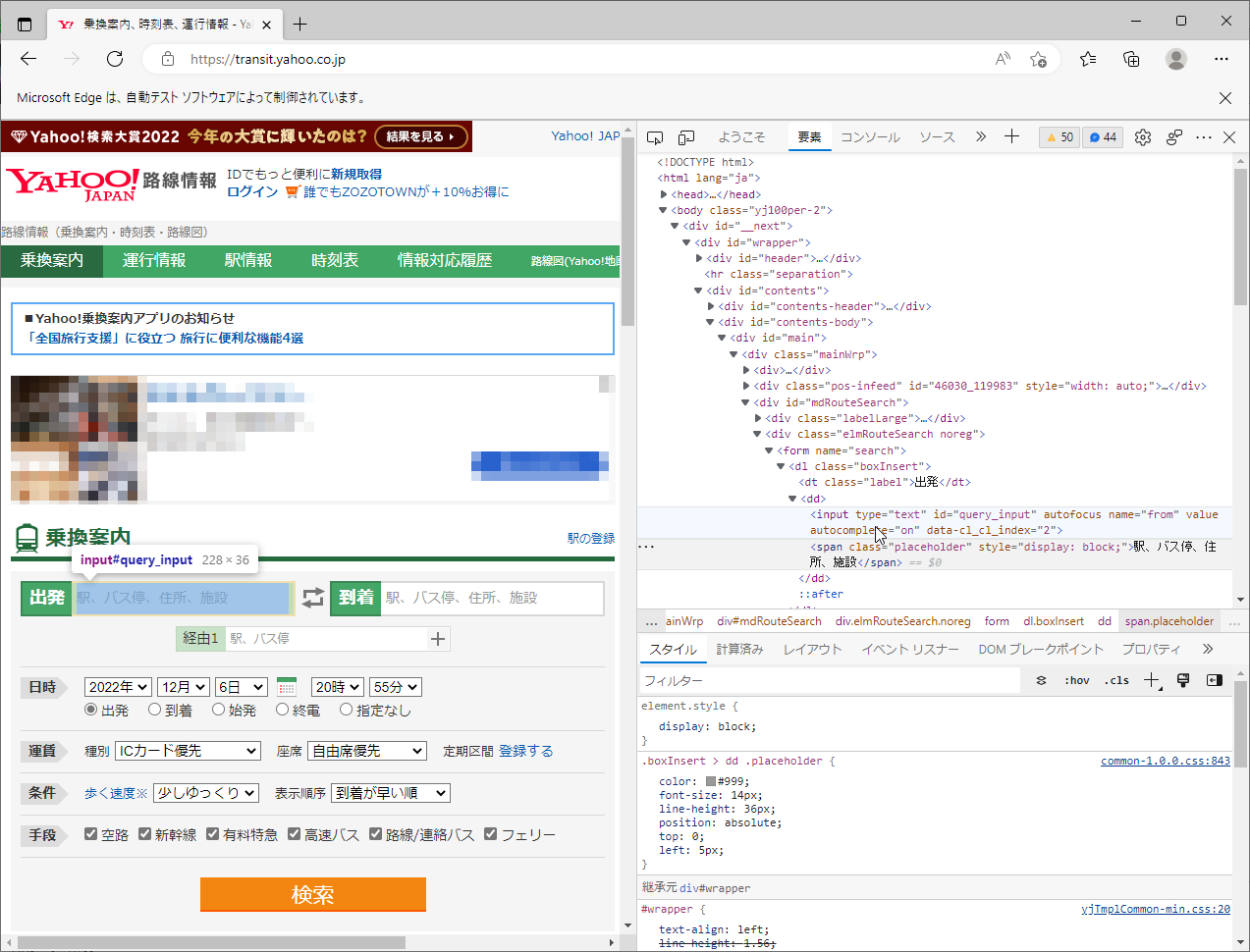
F12キーを押して、ブラウザの開発者ツールを開きます。
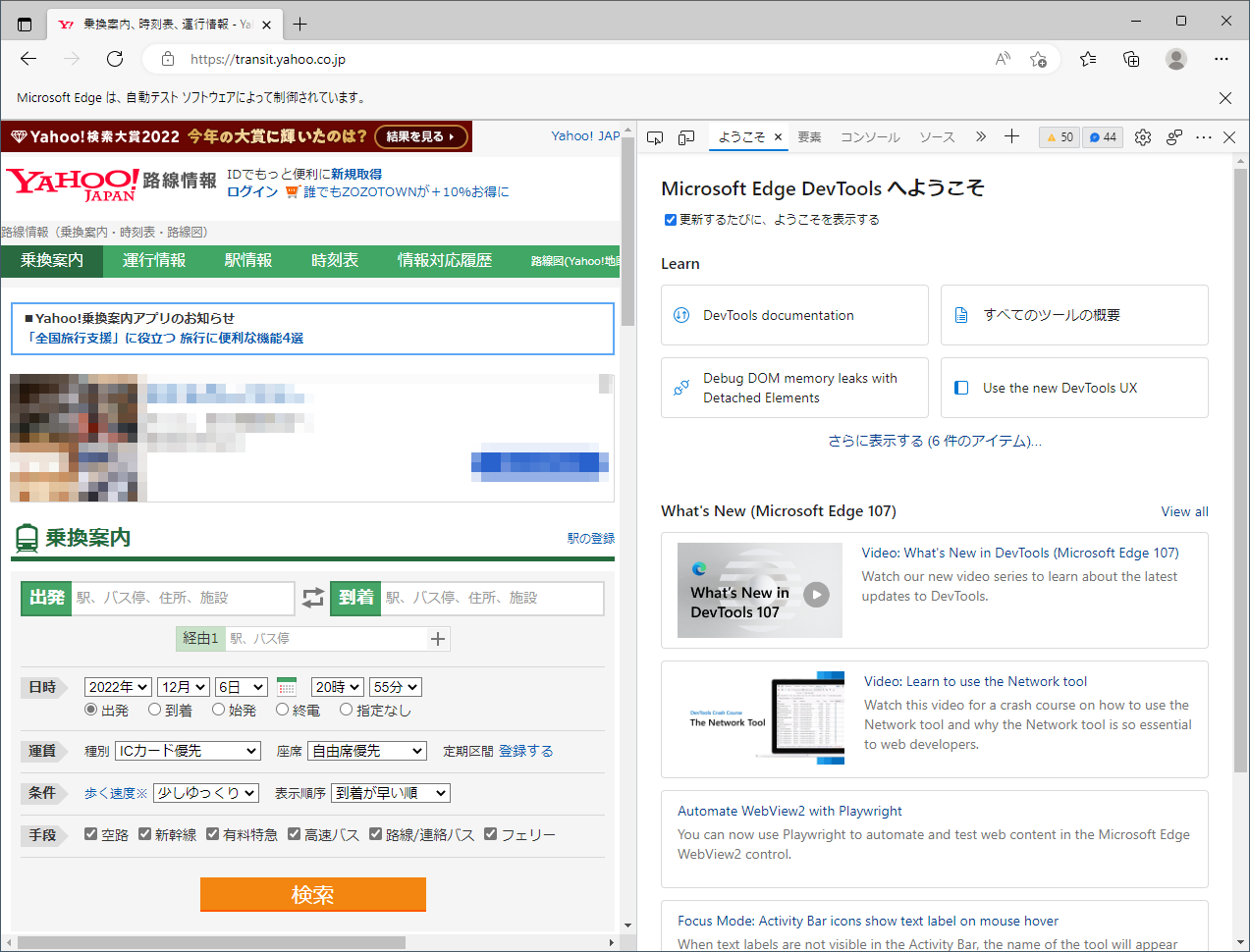
【出発欄】を右クリックして、「開発者ツールで調査する」を選択
先ほどの<span>要素の上に、<input>要素があります。
XPathの取得
HTMLソース側の<input>要素を右クリックして、フルXPathを取得します。
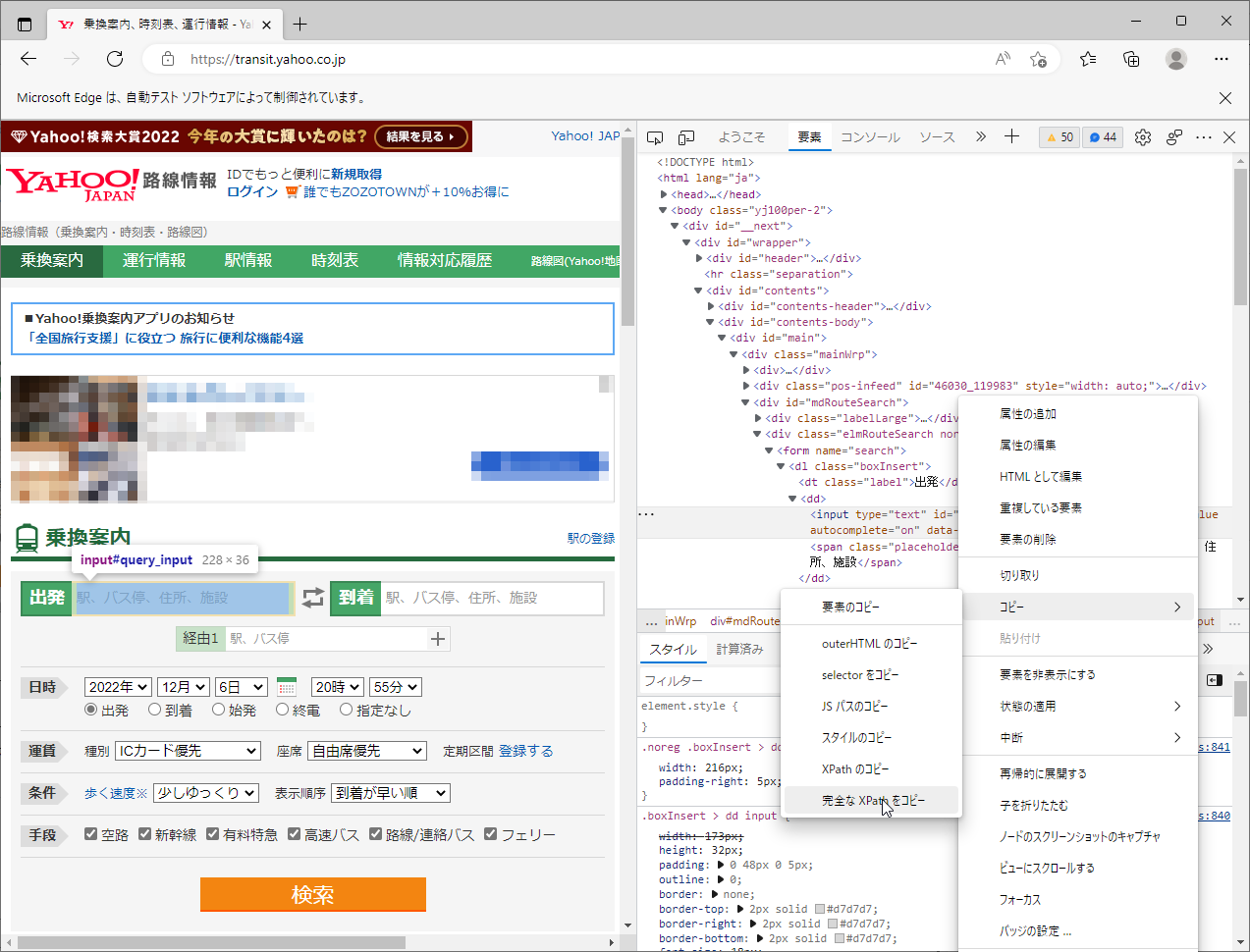
| フルXPath | /html/body/div/div/div[2]/div[2]/div[1]/div[1]/div[3]/div[2]/form/dl[1]/dd/input |
XPathの解析
このままですと長すぎますし、画面のちょっとした変更でXPathも変わってしまいますので、XPath取得ツールで解析します。
XPath取得ツールの【XPath欄】にフルXPathを入力して、【解析】をクリック
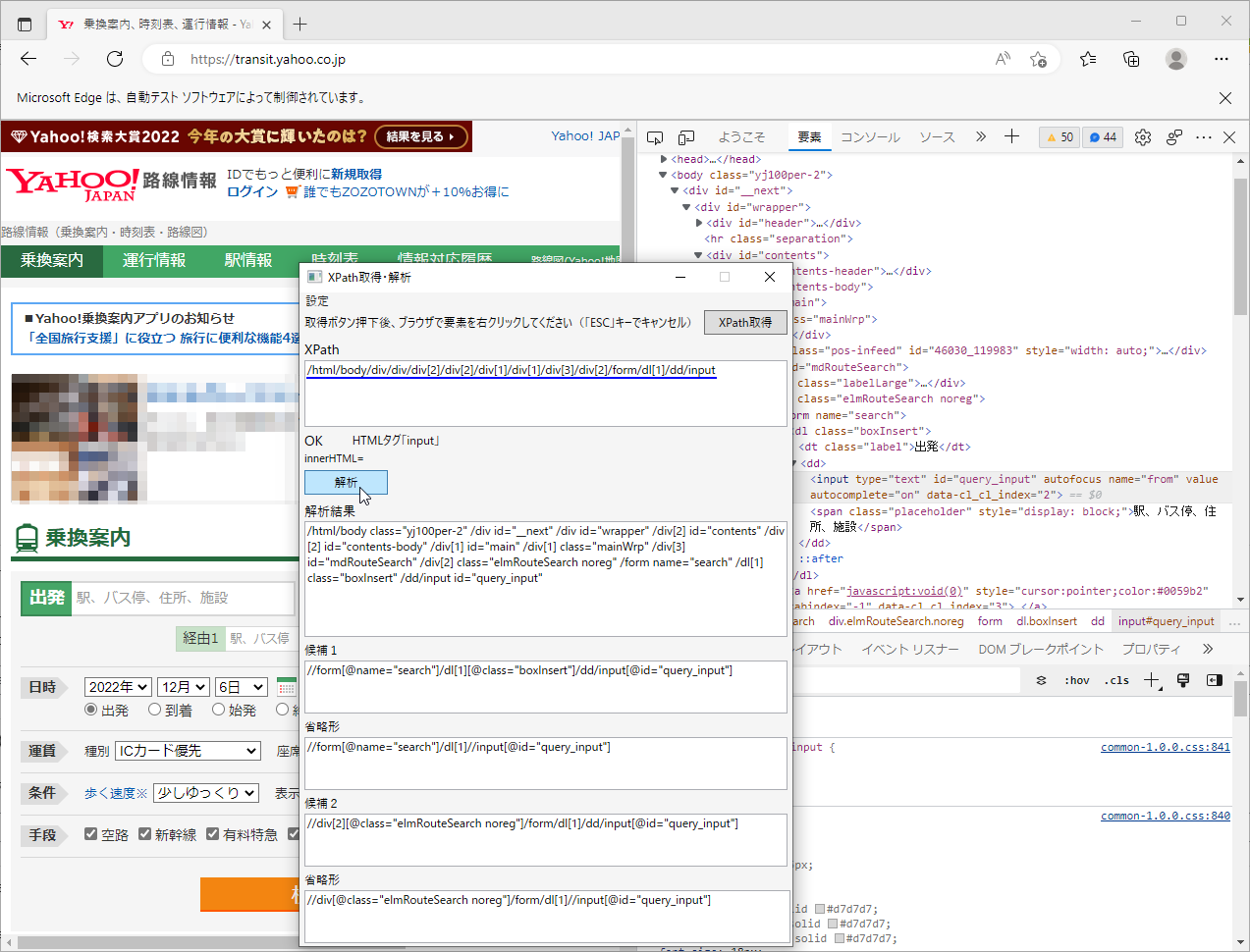
| フルXPath | /html/body/div/div/div[2]/div[2]/div[1]/div[1]/div[3]/div[2]/form/dl[1]/dd/input |
| 解析後 | //form[@name="search"]/dl[1]//input[@id="query_input"] |
操作の実施
得られたXPathでテキスト入力の操作を実施します。
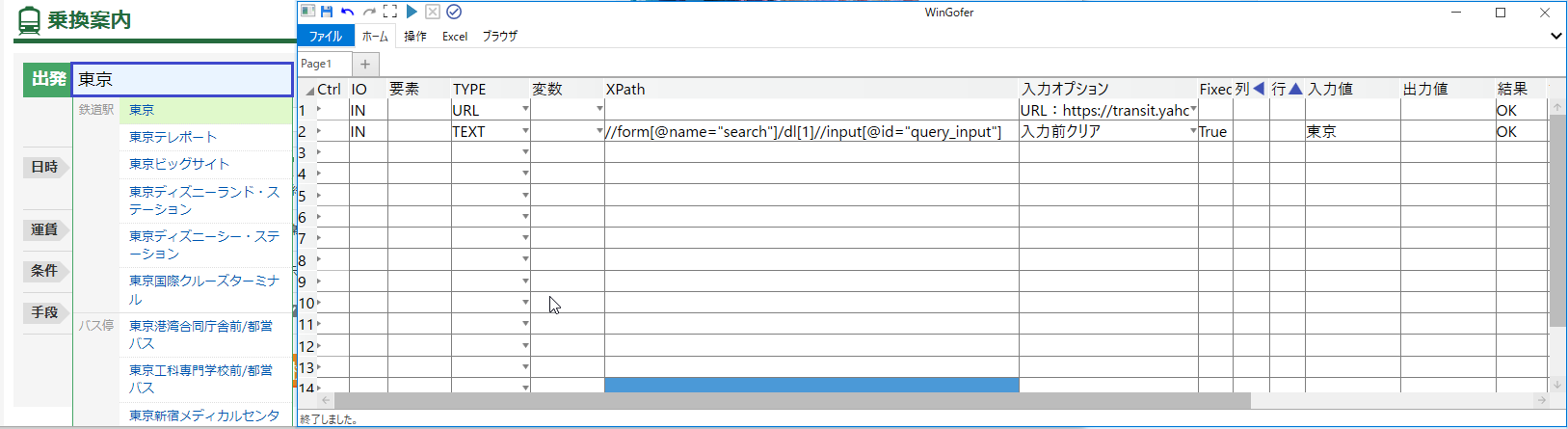
【出発欄】に「東京」と入力できました。
補足(XPathの重複)
さて、解析後のXPathですが、<input>タグにid属性があるにも関わらず
//form[@name="search"]/dl[1]//input[@id="query_input"]
となっています。
HTMLの規約上、id属性は1ページ内で重複して持たせてはいけません。本来であれば
//input[@id="query_input"]
となるはずです。
実際にブラウザの開発者ツールで、短い方のXPathを取得すると以下のようになります。
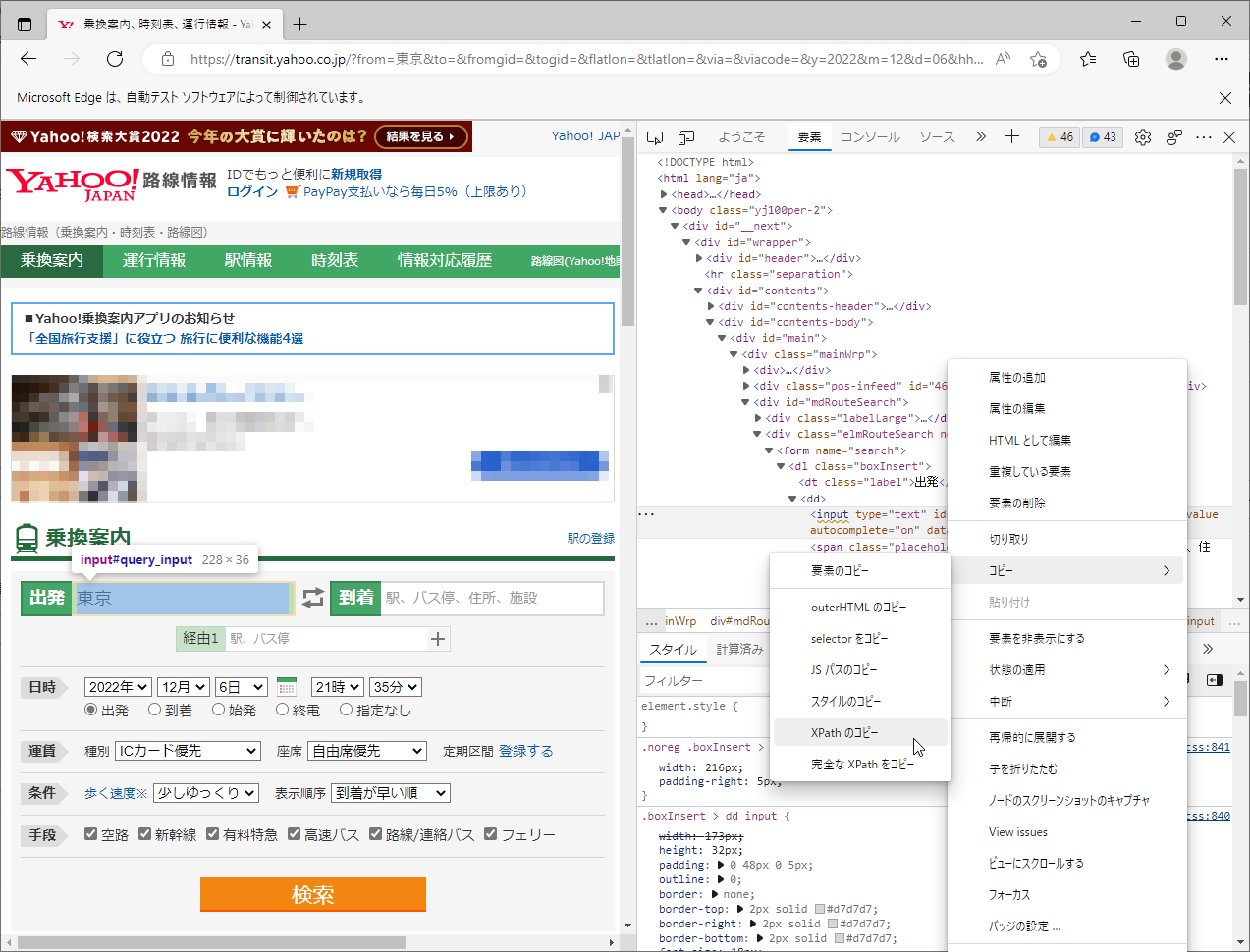
| XPath | //*[@id="query_input"] |
ところが、このXPathを解析すると、指定したXPathでは6個の要素がヒットし、【出発欄】のテキスト要素を特定することができません。
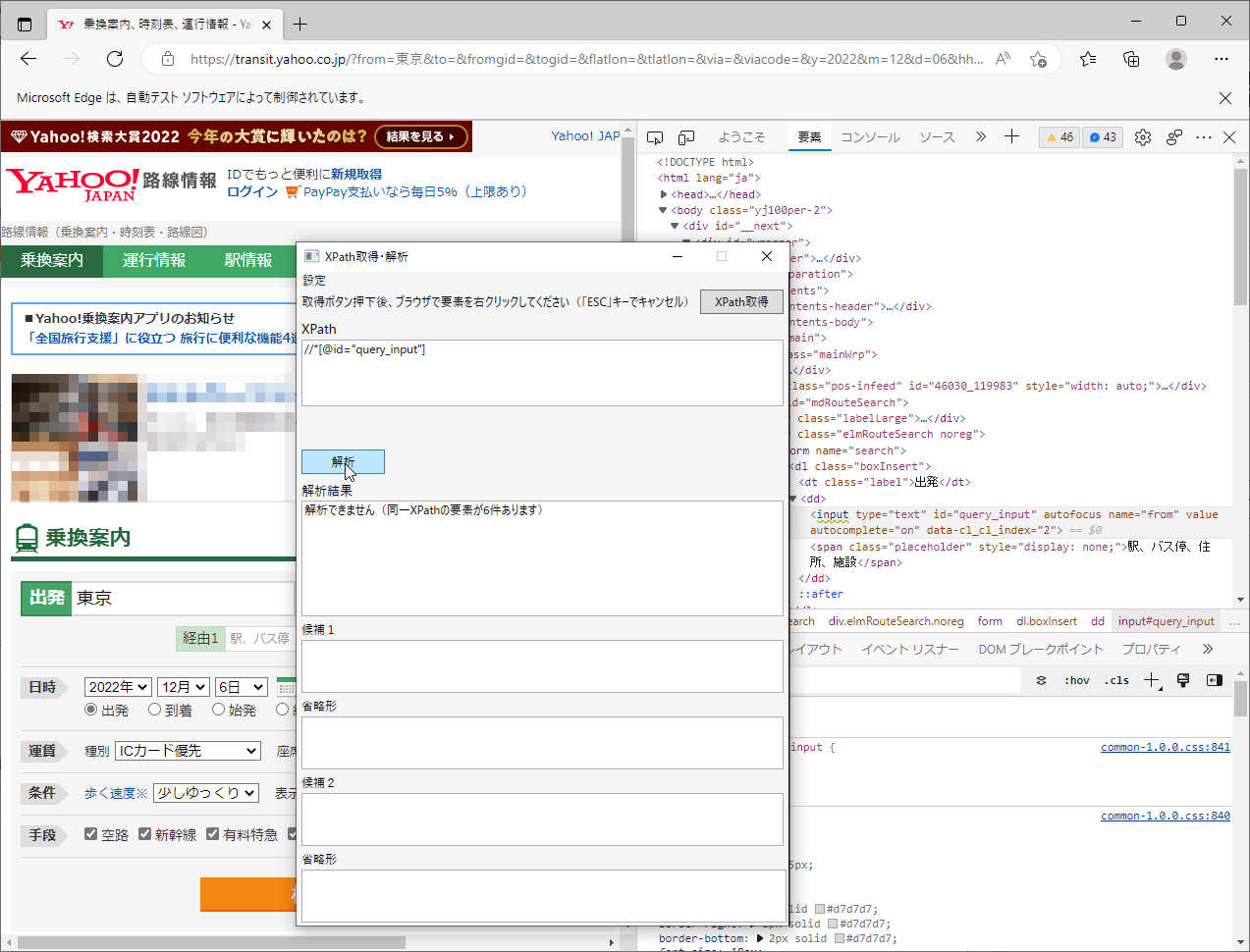
実際にHTMLソースを「"query_input"」で検索すると、6件ヒットします。
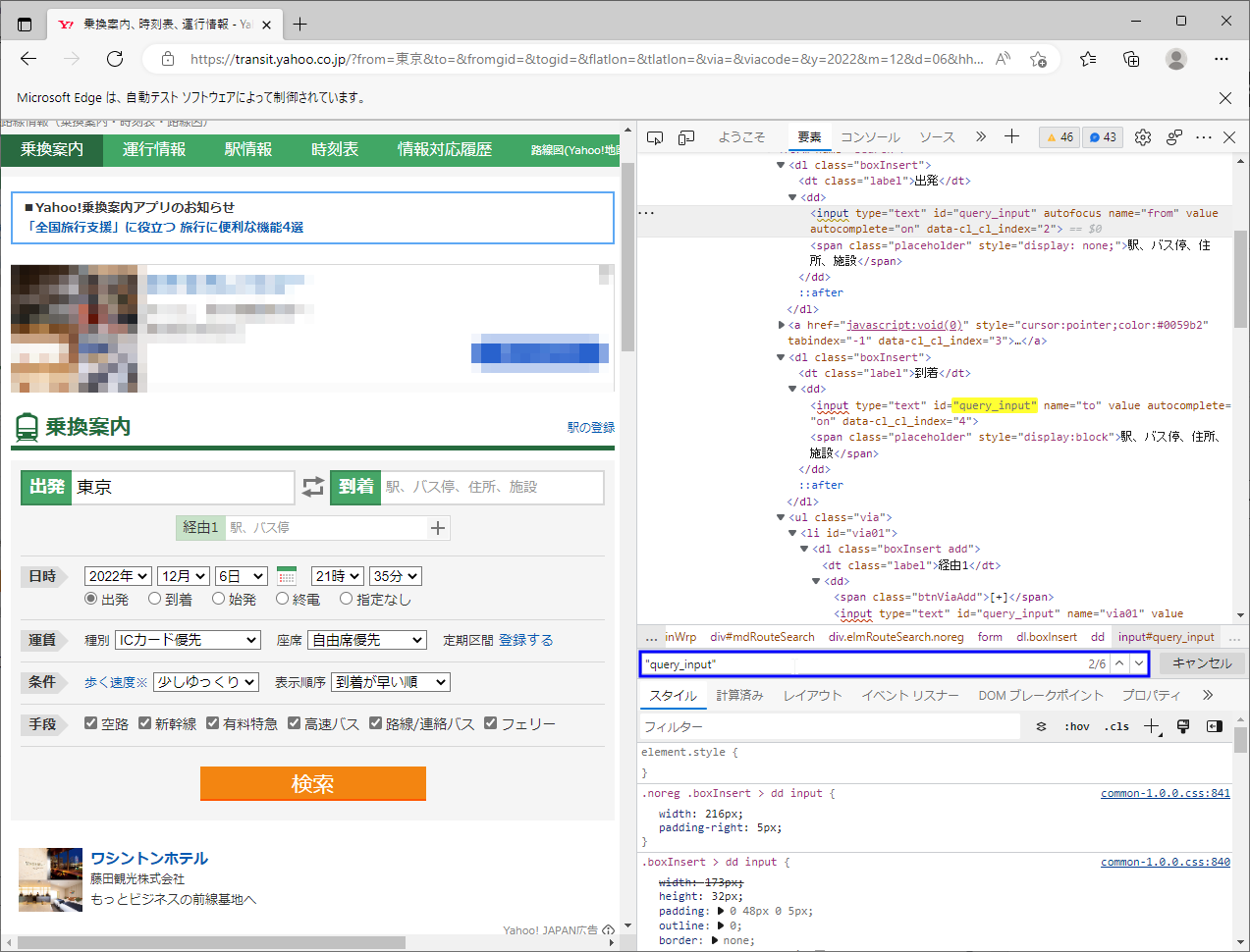
このようにid属性が重複してはいけないのは、HTMLの規約上の話であって、「id属性で要素を一意に特定できることが保証されているものではない」という点に注意しましょう。
操作の実施
なお、WinGoferでは「指定したXPathで要素が2個以上取得できる」時は、結果はNGになります。
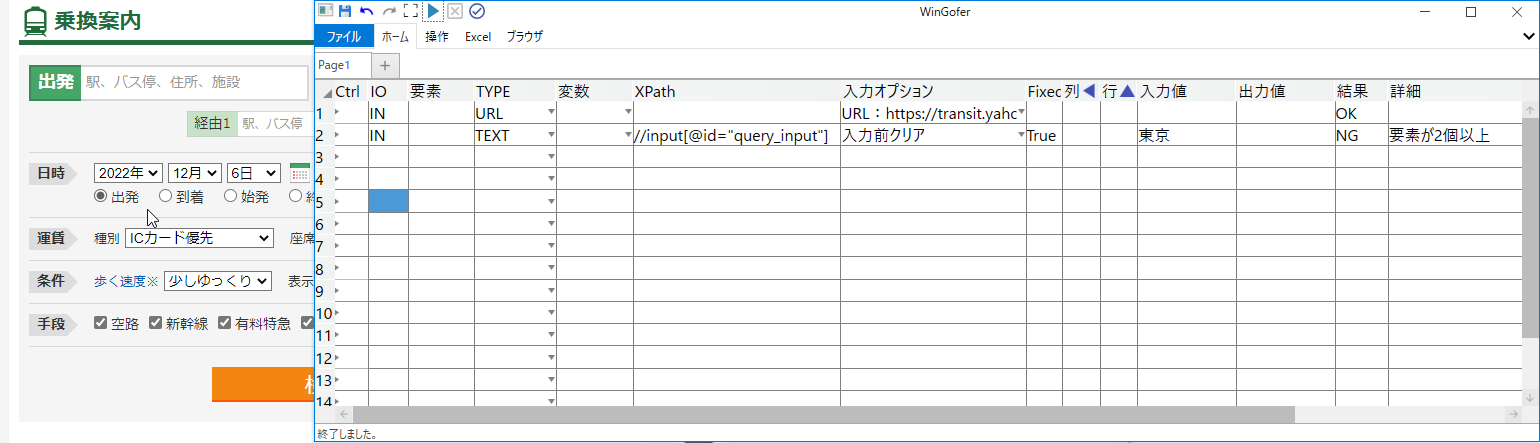
| 結果 | 詳細 |
|---|---|
| NG | 要素が2個以上 |
自分で編集したXPathを解析する
上のケースではid属性だけでは要素を特定できませんが、name属性を合わせることで一意に特定することができます。
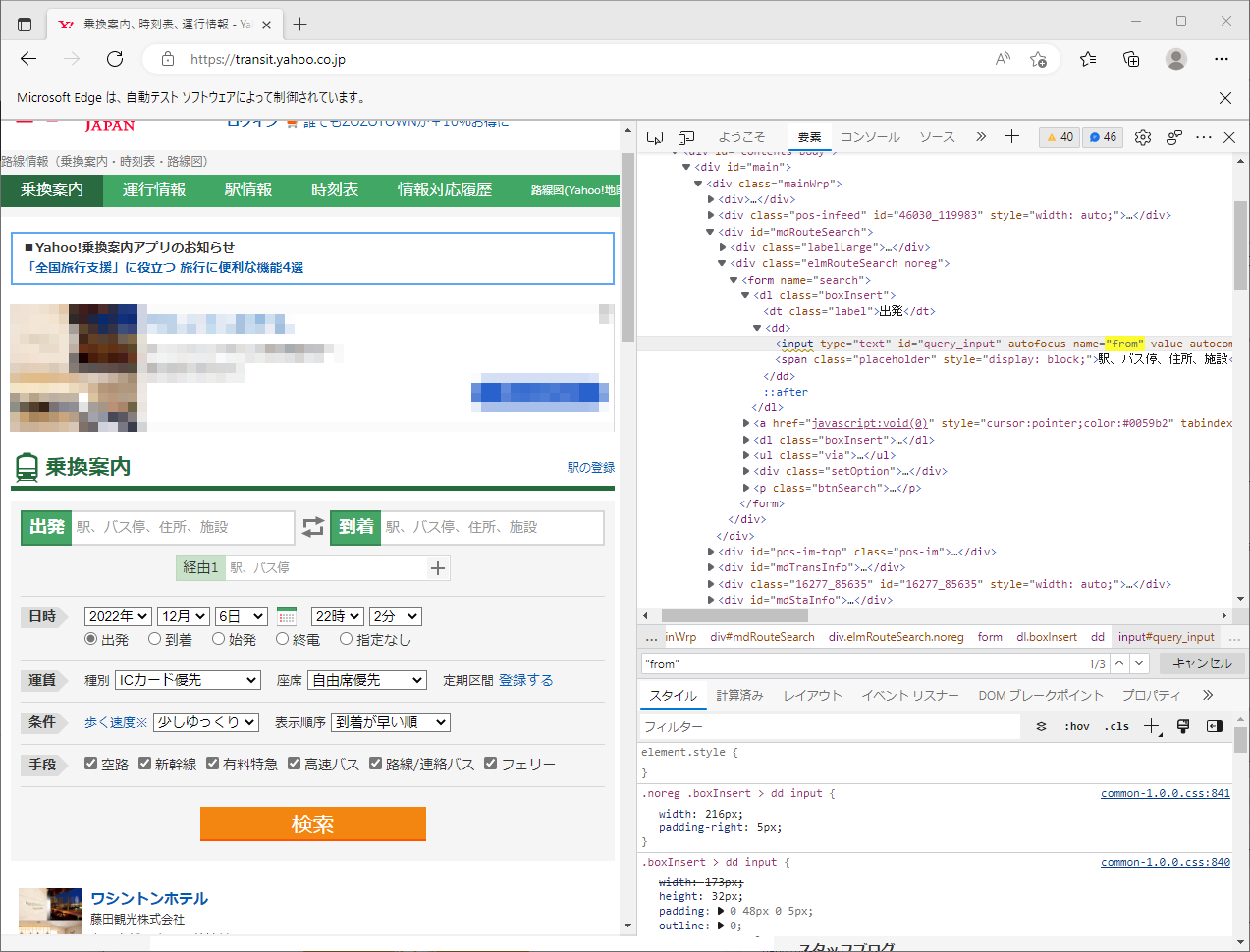
【出発欄】のname属性は「name="from"」となっていますので、XPathは
//input[@id="query_input"][@name="from"]
となります。
XPath取得ツールの【XPath欄】に上のXPathを入力すると、要素が特定され「解析不要」が返されます。
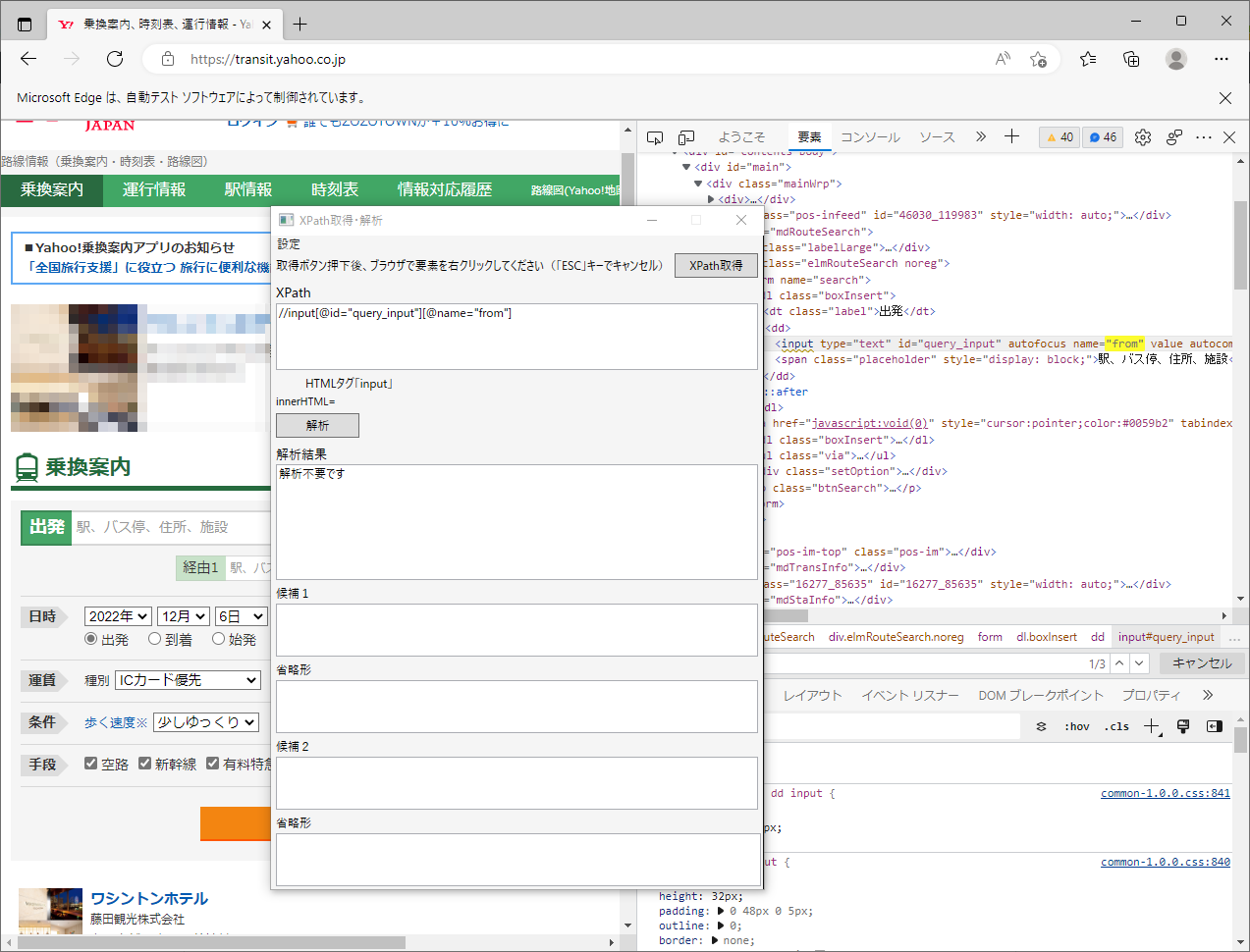
このように、XPath取得ツールでは、自分でカスタマイズしたXPathが正しいかをチェックすることができます。